Complex or Irregular Lung Nodule Detection from CT Scans
Sept 2023 → May 2024
A three-model detection pipeline combining V-Net, YOLOv5s, and DETR to find lung nodules in CT scans, handling both segmentation and localization while reducing false positives.

Overview
This project combines three deep learning architectures (V-Net, YOLOv5s, and DETR) into a single pipeline for detecting complex and irregular lung nodules in CT scans. Each model addresses a different aspect of the detection problem: volumetric segmentation, fast localization, and false positive suppression.
Problem
A radiologist examining a chest CT scan must find nodules that may be only a few millimeters across, partially obscured by surrounding tissue, and presenting as either solid masses or faint ground-glass opacities. This is difficult under clinical time pressure. Missed nodules have serious consequences, but false positives lead to unnecessary biopsies and anxiety. Automated detection handles the repetitive survey work and surfaces candidates for the radiologist to evaluate.
Approach
No single architecture handles all aspects of nodule detection equally well, which is why the system uses three complementary models.
V-Net segments nodules in 3D. It understands that a CT scan is a continuous volume of tissue, not a collection of independent images. Using residual connections, it learns the irregular shapes that simpler approaches miss. The input is CT scan images paired with segmentation masks; the output is a precise delineation of where the nodule ends and the lung begins.
YOLOv5s localizes nodles in each CT slice. It divides the frame into an N×N grid and assigns each cell a probability of containing a nodule along with bounding box coordinates. The single-pass architecture makes inference fast enough for clinical use, and integration with V-Net's segmentation output means the two models correct each other rather than operating independently.
YOLOv5s with Shape Modeling extends localization with geometric descriptors (compactness, eccentricity, and solidity) that distinguish solid nodules from ground-glass opacities and discard false positives that intensity-based detectors would accept.
DETR uses learned queries that attend to the entire image globally rather than dividing it into a grid. This reduces false positives that slip through other models, particularly for nodules near the pleural wall or mediastinum where local context is insufficient.
How It Works
The dataset is the Lung Image Database Consortium (LIDC-IDRI) collection, providing CT scans with nodule annotations from multiple radiologists. Images were resized to 256×256 pixels to preserve diagnostic detail while remaining tractable for training. Nodule presence was encoded as a binary label per slice, and the data was split into training, validation, and test sets before augmentation with rotations, flips, shear transformations, and zoom.
V-Net was trained with an encoder-decoder architecture using batch normalization and ReLU activations. YOLOv5s was trained for single-pass bounding box prediction. DETR was trained with its standard transformer encoder-decoder configuration.
Results
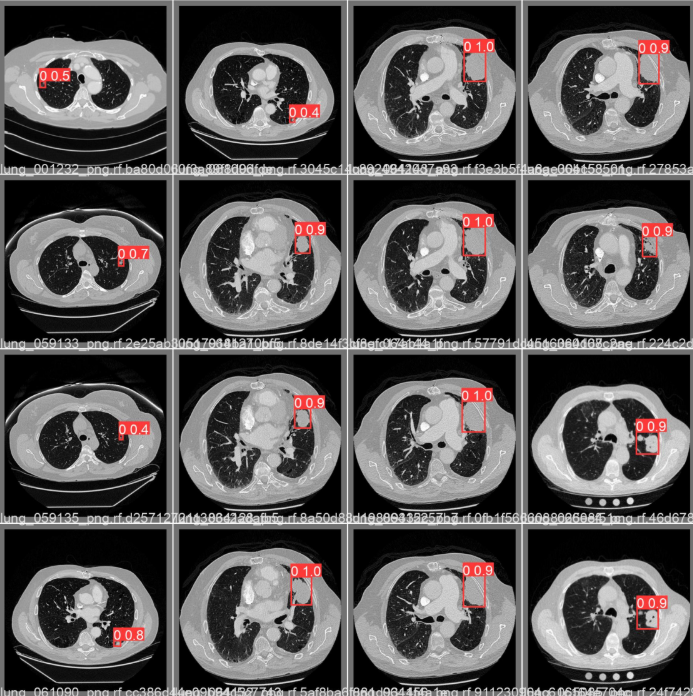 Sidenote: Sample detections by YOLOv5s
Sidenote: Sample detections by YOLOv5sV-Net achieved strong segmentation performance measured by Dice coefficient and Intersection over Union. YOLOv5s demonstrated accurate multi-nodule detection per slice at inference speeds compatible with clinical workflows. DETR's primary contribution was suppressing the false positives that the faster models, optimized for recall, inevitably produce.
Tech Stack
- Language: Python
- Deep Learning: TensorFlow, Keras, Ultralytics (YOLOv5s)
- Data Processing: Scikit-learn, NumPy
- Dataset: LIDC-IDRI (publicly available)