Agentic AMS Platform
Feb 2025 → Jan 2026
An autonomous multi-agent system that detects, diagnoses, and resolves production incidents end-to-end, with a human in the loop and a vector-indexed knowledge base consulted at every step.

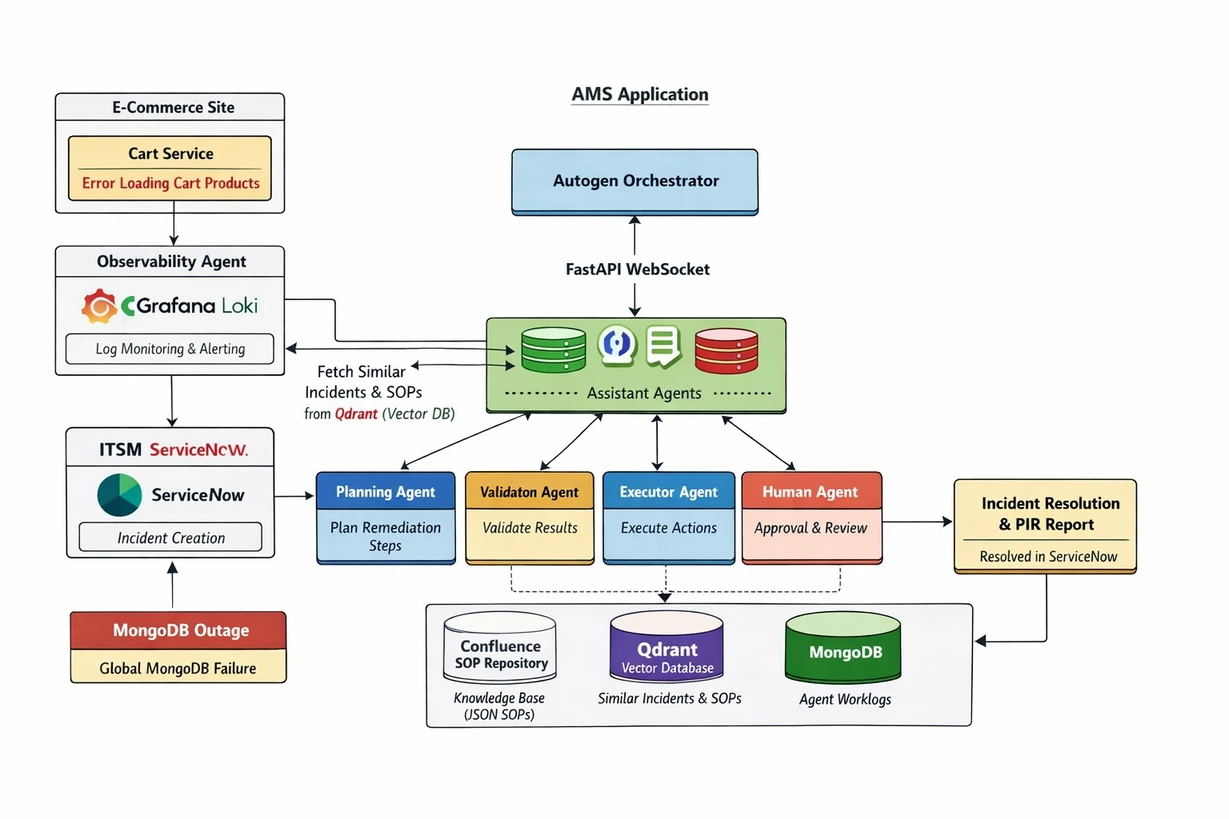 Sidenote: AMS Architecture
Sidenote: AMS ArchitectureOverview
The Agentic AMS Framework is a multi-agent system that detects production anomalies, retrieves relevant remediation procedures from an organizational knowledge base, executes a remediation plan through real infrastructure tooling, and validates the result. A human approval gate sits between planning and execution, ensuring no irreversible action happens without operator consent.
Problem
On-call engineers get woken at 3 AM by Grafana alerts, then spend significant time tracing causation through logs across distributed services. The alert indicates something is wrong but doesn't explain what, why, or how to fix it. The system automates the detection-to-resolution pipeline while keeping a human in the loop for the decisions that matter.
Approach
The system is organized into four layers, each with a distinct responsibility.
Observability. Application logs flow into Grafana Loki, which triggers keyword-based alerting rules. An Observability Agent connects to the dashboard over a persistent WebSocket, reads alerts as they arrive, and checks ServiceNow for existing tickets. If none exists, it creates one; if one already exists, it skips duplicate creation. This deduplication logic prevents downstream agents from processing the same alert repeatedly during flapping events.
Knowledge retrieval. An agent that detects problems but can't fix them is just a notifier. The RAG pipeline uses Qdrant, a vector database holding the organization's Standard Operating Procedures sourced from Confluence via batch ingestion. When the Agent Orchestrator receives an incident, it fetches the most semantically relevant SOP so that agents reason with institutional knowledge rather than from scratch.
Planning and execution. Three agents handle remediation:
- The Planning Agent receives the incident description and retrieved SOP, then produces an ordered remediation plan. It does not execute anything.
- A Human-in-the-Loop checkpoint then presents the proposed plan to a human operator for approval or rejection. This is not ceremonial. It is the mechanism that earns the system the right to be trusted with real infrastructure.
- Upon approval, the Executor Agent works through the plan step by step, calling tools (HttpRequest for API interactions, JenkinsRollback for deployment reversions, ReadPodStatus for Kubernetes pod queries). After each step, the Validator Agent independently verifies whether the step had its intended effect. If validation fails, the Executor retries. If it succeeds, the pipeline advances.
Resolution. When all steps pass validation, the ServiceNow ticket is closed and the on-call engineer is notified.
How It Works
- Grafana alerts trigger on anomalous log patterns.
- The Observability Agent reads the alert, checks ServiceNow for an existing ticket, and creates one if needed.
- The Agent Orchestrator fetches the most relevant SOP from Qdrant.
- The Planning Agent produces an ordered remediation plan based on the incident and the SOP.
- A human operator reviews and approves (or rejects) the plan.
- The Executor Agent runs each plan step using infrastructure tools.
- The Validator Agent verifies each step's outcome.
- On full resolution, the ServiceNow ticket is closed.
Tech Stack
- Agent Orchestration: Microsoft AutoGen
- Vector Database: Qdrant (Python SDK)
- Observability: Grafana, Loki
- Ticketing: ServiceNow
- Knowledge Source: Confluence (batch ingestion)
- Tools: HttpRequest, JenkinsRollback, ReadPodStatus